








这些年来,经历了不同形态的业务和不同规模的运维,今天我主要和大家分享我这些年来关于运维自动化的一些认识和实践,包括如下八点:
自动化需要整体规划
自动化的基础是标准化
首先从持续交付开始
DevOps的四观
善于借助研测的力量
不一定强依赖CMDB
以NO OPS为最终目标
Docker等不是干掉运维
以下为详细内容,敬请欣赏。
1. 自动化需要整体规划

没有整体的规划始终觉得运维是在建一个个的工具,没法形成递进式的实现策略。
边界的识别是通过分层体系来构建DevOps自动化工具栈,而不是用一个工具解决所有问题,和智锦的观点类似:
千万不要以为puppet/salt/ansible所管理的配置工具能够解决所有运维自动化的问题(不过小企业运维另论哈)。
运维场景是寻找自动化平台实现的驱动力,可以衡量成本和收益比,不要为了自动化而自动化。
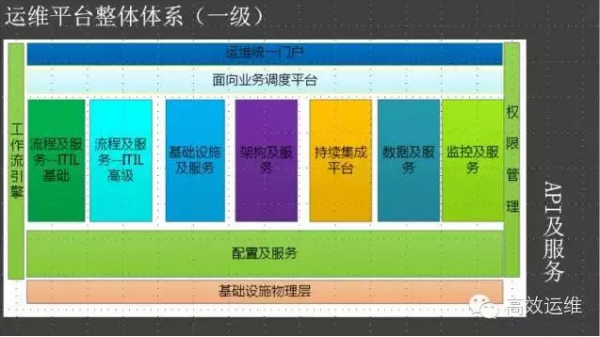
我把其中的每一块都抽象成服务,比如说基础设施及服务(IAAS部分)、配置及服务、流程及服务(ITIL部分)、架构及服务(PAAS部分)、数据及服务、监控及服务等等。
持续集成平台,我把他单独提出来,它很特别:是一个应用交付的主线,他涉及的点很多,自动化编译、自动化测试、自动化部署等等,另外横跨了多个团队,带来的收益很高。
监控及服务也很特别,对于我来说,一切数据都应该有监控的能力,所以我更多觉得监控是一种数据化的应用,和数据分析一样,个人监控观点是“先数据、后监控”。
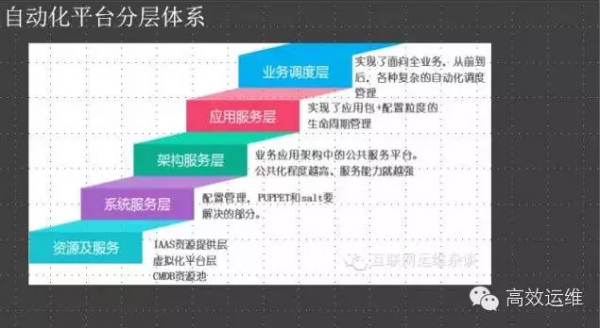
我习惯把它们映射到对应的层次上,对每一层的自动化手段都不一样,其实我觉得底层的资源及服务和系统服务层应该越简单越好,好不要在系统层面上有依赖,比如说特殊的网络设置,特殊的DNS设置。
严格禁止系统内部调用通过运维系统路径,比如说DNS、LVS,目的就是为了简化服务间的依赖,对于运维来说部署一个完整的服务,就要做到部署一个包这么简单。
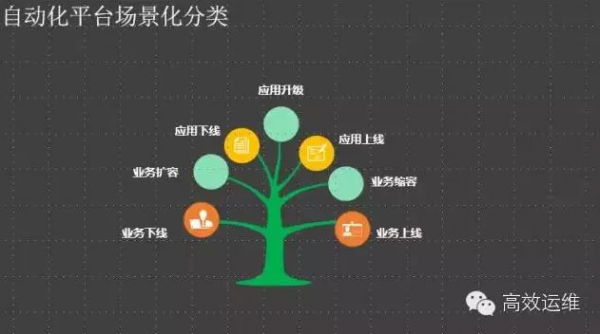
另外一个维度就是运维场景的识别,业务形态不一样,场景就不一样,逐步挑选对运维收益大的部分自动化实现它。
2. 自动化的基础是标准化

自动化平台必须是经验交付平台,而非技术平台。
技术是经验的一部分,而我想强调的是,做每一个自动化平台都需要搞清楚:
自己的自动化平台要解决的问题;
能达到的收益;
使用user是谁等。
我将在后面持续交付平台中继续体现这个思路。
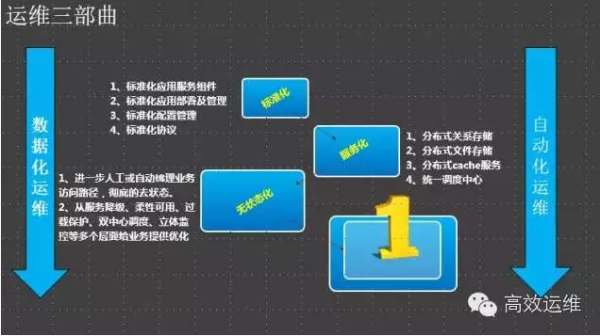
我个人认为标准化能体现你对运维理解的精准度及勇气。标准化的推进很需要运维的勇气,否则没法影响研发按照自己的节奏走:
标准化是让人和系统更有效率和效力的做事:效率是快速的做事、效力是正确的做事。
在UC,我完全是按照这套方法论和节奏去推进运维工作,自动化一定是随着业务发展而发展的。
更需要指出的是,越到后续阶段,运维工作更是需要和研发、测试深度合作完成,所以运维自动化不能忽略研发、测试。另外:
各个部分对自动化都有影响,比如说标准化部分的配置标准化(让配置管理更简单);
服务化部分的组件向公共服务组件迁移(服务通过API暴露,让服务的管理更简单);
无状态化的服务双中心改造,服务高可用也是依赖技术而非人来解决。
接下来举两个小例子。
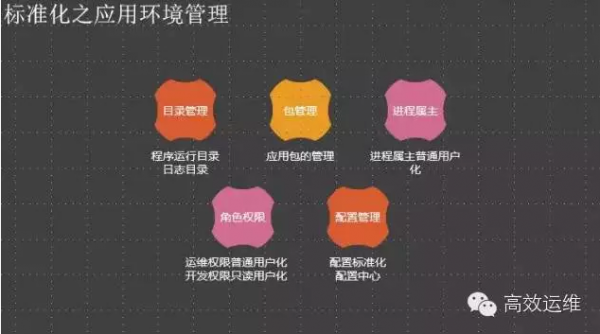
这个图中两个重要的标准化工作就是配置管理标准化和应用包的标准化,基于此构造的持续部署系统非常简单,不用兼容业务的个性化特点。

很庆幸,我们把所有的java容器全部迁移到自研的容器上,我们的容器接管了所有共性的研发服务,比如http服务,缓存服务、配置服务…完全插件化的服务容器。这是可运维性一个很好的例子。
3. 首先从持续交付开始

有些人问,运维自动化该如何开始?
我的一般建议都是把持续集成或者CMDB作为开始主线。持续交付带来的是多个团队的利益和价值,这个工作可以由运维牵头来解决,运维解决的方法可以先从持续部署开始,然后在对接上面的持续集成:
持续部署系统的建设可以联合研发、测试和运维来建设,方便推广,降低噪音(反对声)。
另外,持续交付系统会反向推动运维内部的一些标准化工作,比如说环境标准化、应用标准化等等,因为你的部署要越来越简单。
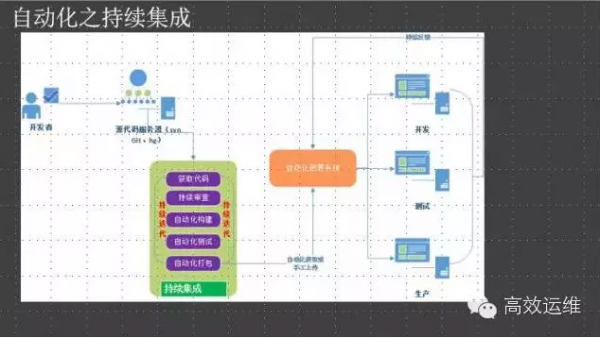
持续集成+持续部署等于持续交付,实现面向用户产品功能的持续交付。
但持续集成仅仅是面向应用交付的能力封装,还不能够成为运维自动化能力的全部,往上有面向业务的全流程自动化(调度平台,实现任务封装),往下有OS级的自动化(配置管理)等等。
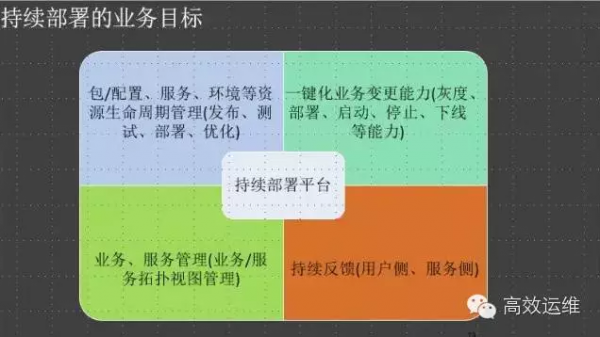
这是我做持续集成系统定的一个业务目标(供参考)。持续部署必须要包含对要管理对象的生命周期的管理、一键化变更管理能力,同时还需要对变更后的结果做到持续反馈。业务和服务拓扑是基于之前配置标准化的一个能力实现,没有放到CMDB中。
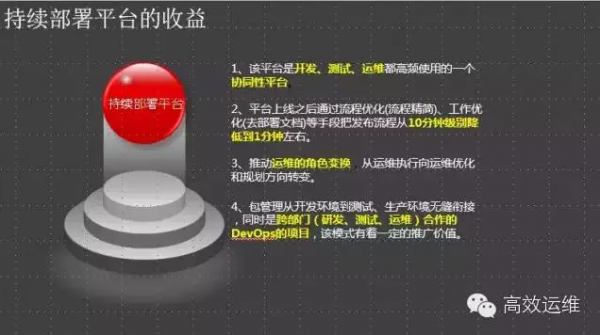
当前我们实现持续部署能力有有两套方案,目前UC使用的基于Cloud Foundry封装的UAE平台。
这种对应用有改造要求的PAAS平台不是太好:
一则太复杂,二则底层服务有依赖(比如agent重启,业务进程也要重启)
第二种方案,就是无侵入的运维方案,把运维对持续部署的控制,封装成标准的事件,大家看看RPM包里面的能力就好理解了,再结合持续集成和持续交付的理念,把他们做成可视化。
4. DevOps的四观

我自己对DevOps的一点认识:
文化观:突破部门墙、深度合作的文化。
价值观:持续优化、共享责任、杜绝浪费、关注用户。
共享责任是合作的内在细化,谈合作太虚无缥缈。
思维观:精益、价值、跨界、敏捷
工具观:自动化平台集(实现价值的交付)+数据化平台集(实现交付价值的衡量)

为什么不是DevTest?为什么不是TestOps?为什么不是DTO?
我自己的理解是D和O代表面向用户服务能力的两端,两端能力的对接是优化的极致。
运维人很多时候都和开发提运维友好,缺忽略我们自己要做的东西也要研发友好。所以很多时候不要站在“我”的需求立场上,而是“我们”.
14年DevOps调查报告,指出要“自动化、自动化还是自动化”。
运维自动化就是要解决运维团队服务能力的吞吐率和延时问题,也即如何更多、更快的提供运维服务,其实是和线上的服务能力一样的。
需要思考的问题是,制约我们服务能力的关键因素,是资源约束(服务器不够)、还是架构约束(架构公共化能力不强)、还是运维服务约束(运维基础平台DNS/LVS服务能力)?
这个可以不断的驱动我们思考DevOps的产品形态和状态了。当然人的意识很重要哈,D/O分离应该走向DO合作。
5. 善于借助研测的力量

运维自动化的工作少不了研发测试的支持,有时候运维复杂的系统封装,结果在研发侧做一些小小的改造就可以了,然后部门墙和彼此的强势文化导致DO是分离,而不是合作。
我举两个例子,配置管理和名字服务。

define.conf是把其他底层配置在研发、测试和生产环境的差异消除掉,底层配置文件中采用变量配置方法,通过define.conf在三个环境中定义具体的值来简化配置管理,持续部署系统就变得极度简单,因为只需要管理一个define.conf配置即可。
因为我们业务规模很小,所以没有提配置中心,配置中心在规模服务化运维下,必须要构造的一个基础服务。需要研发深度支持配合!
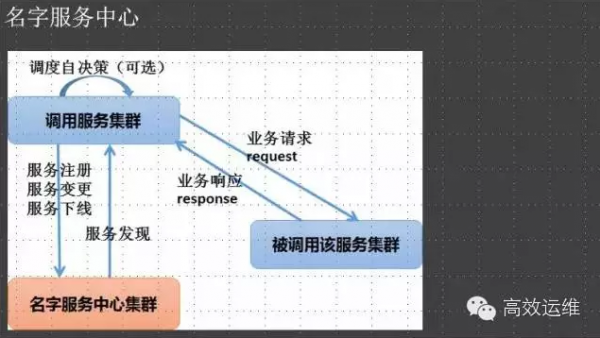
名字服务中心是我的个人情节,终于在UC变成了现实。
我相信很多中小企业的服务调用都是通过DNS获取服务地址来实现调用的,这个缺点就是故障的时候,需要运维深度参与故障处理(TTL、JDK缓存等等)
我们为此特意建立一个名字服务中心,通过它来实现服务名到实例的具体映射,同时调用端统一实现服务的调度、容错。
现在内部业务故障,基本上不需要运维参与切换和处理了,大大简化运维故障处理系统的复杂度,还有服务扩容的时候,服务自动注册不需要人为修改配置文件,更加的自动化。需要研发深度支持配合!
6. 不一定强依赖CMDB

不要觉得CMDB是自动化的前提。cmdb和自动化平台的关系有两种:
自动化平台与CMDB的关联发生在某些场景下的某些流程片段,比如说业务上线流程中的资源自动化申请,从CMDB获取信息。
自动化平台把变更的信息回写到CMDB,比如说应用部署系统/DNS系统/LVS系统等信息,目标是把CMDB作为元数据管理的平台,它可以收敛之上服务之间的数据获取接口。
当前我们是这么干的,但是发挥作用还不大。特别是业务规模不大,而业务变化不是非常频繁时,CMDB的管理仅仅只需要记录资源被谁,用在哪个业务上即可。在公有云IaaS平台下,CMDB的形态就更简单了。
7. 以NO OPS为最终目标

运维自动化以挑战每个运维职责部分的“no ops”为目标,比如说服务器交付/应用交付/组件服务交付等等。
最终这种”no ops”的运维平台可以让研发自己去完成(持续部署交给研发),也可以让用户来帮我们决策完成(容量驱动变更)
把这些专业的服务能力可视化封装起来,提供API,供其他关联服务调用,体现自服务能力。每个人运维人应该带着可视化管理的要求去面对自己的日常工作,这样可以确保自动化的能力每个人都能获取,并且执行结果是一致的。
8. Docker等不是干掉运维

个人认为对运维的影响不是这些技术,而是基于该技术之上的产品化能力。但是不同服务能力的结合,爆发出来的能量需要运维人注意:
比如说IaaS平台和Docker技术结合,服务调度和名字服务中心结合,微服务对技术架构标准化影响。
因此DevOps不仅仅是对D有Ops能力的要求,对O来说,也要有Dev能力的要求。另外大家可以看看运维还有哪些工作,就知道这些技术对运维的影响了。























