








亚马逊云服务(AWS)是全球大的云服务提供商,目前它在全球拥有24个地理区域,77个可用区(AZ)。如此庞大的云基础设施是如何运维的,一直以来都备受业界关注,而多年来AWS很少谈及这个话题。
在今年的亚马逊re:Invent在线峰会上,AWS首次揭开了自己云基础设施的神秘面纱,从数据中心的供电管理系统,云数据中心的延迟,到芯片的研发等等,虽然只是冰山一角,但可以从不同的视角更加直观、清晰的了解AWS是如何修炼“内功”的。
让深度睡眠不再“奢侈”
在AWS全球基础架构和客户支持资深副总裁Peter DeSantis看来,“AWS保持如此庞大、复杂的云基础设施的稳定性和可靠性没有捷径,是靠一步一步的积累走出来的,必须对每个细节进行研究”。
对于负责数据中心运维的工程师而言,充分的睡眠是相当“奢侈”的东西,因为他们会时刻收到来自数据中心基础设施中的各项报警邮件、短信等信息,Peter也不例外。
Peter通过数据中心的配电系统和UPS管理来展示其如何通过良好的数据中心运维手段来保证自己的睡眠质量,十分形象。图上的横轴为云数据中心的复杂度,纵轴是破坏半径,当AWS云数据中心的发电机、配电系统和UPS复杂度越高,破坏半径系数越高的时候,Peter的睡眠质量就处于Insomnia的失眠状态;而当Peter通过优化AWS云数据中心基础设施之后,其睡眠质量得到了明显改善,处于了Deep Sleep深度睡眠的状态。
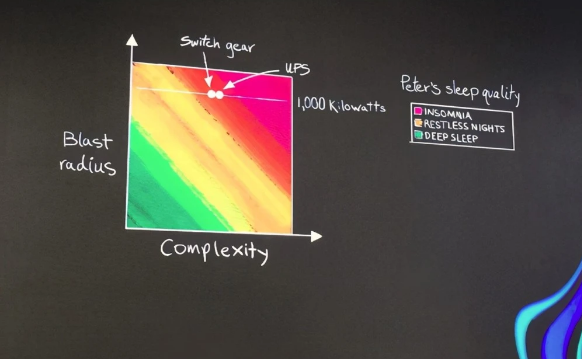
Peter是如何做到的?总体来看,关于AWS云数据中心运维可总结为可靠可控,降低管理复杂度。
AWS云数据中心的供电系统由发电机组、配电系统和UPS等组件构成。AWS为其发电机组配备了冗余的发电机来提升可靠性。
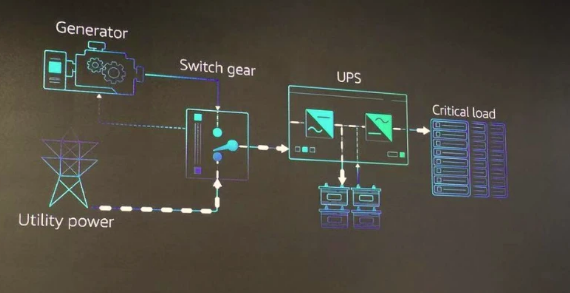
相比于发电机可以通过冗余来作为基础的思考,配电系统和UPS就要复杂的多。“不论是GE、ABB还是施耐德,它们的配电开关系统功能都很完善,但挑战是对于AWS这样的超大规模云数据中心而言,并不是每个功能都适用”,Peter坦言。
说白了就是配电开关的嵌入式软件束缚了AWS数据中心运维的手脚,而AWS凭借多年的运维经验很清楚哪些功能适合,哪些根本不需要。比如有的功能,AWS不需要;而有的,AWS有更加优化的方案。
Peter总结了三个方面:第一,当发现软件系统的Bug,AWS工程师的响应很快,而等配电供应商去修改周期更长;第二,有些功能与实际用途不匹配;第三,AWS需要经常优化自己的管理系统、流程等,嵌入式软件无法保证可控性。
基于此,AWS重写了配电控制系统,从而为其配电系统带来了可控性,运维也更加简单。
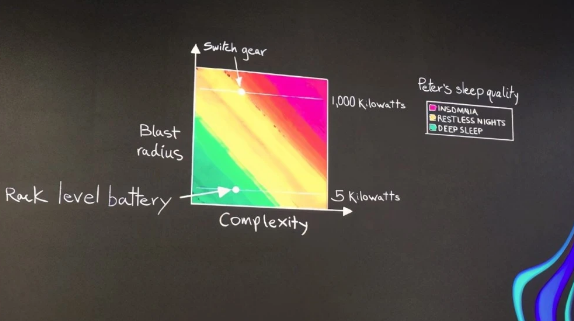
同样对UPS的控制系统,AWS也通过重写UPS控制系统来满足自身对功能的需求。Peter特别介绍了如何为UPS电池减重,从而大大降低了UPS电池管理的复杂度。

标准的一兆瓦UPS电池重达12000磅,AWS重新定制了UPS电池,做成了5000瓦一个,可插拔的放入到机架中,并通过专有控制系统来对UPS进行管理。这样做的好处的显然的,“UPS电池单元体积和重量降低后,破坏半径会降低,可插拔的方式让工程师可秒级换掉损坏的UPS,运维复杂性大大降低”,Peter说。
“这些是AWS设计基础架构中最重要的思维模式,思考它的破坏半径大概有多大,同时它的复杂度有多大,从这两个维度想办法去提升运维稳定性”,Peter总结说。这也让AWS云数据中心的UPS的冗余系统拥有了7个9的可用性,远超行业的平均水平。
“一毫秒”是关键
从电商业务起家的亚马逊,最早的数据中心位于美国西雅图,随着业务的发展,亚马逊开始在美国多地建立数据中心,以满足不断增长的数据规模和业务需要。
在数据中心的地理位置选择上,亚马逊会综合考虑诸多自然条件因素,比如雷电、龙卷风、海啸、地震等,这就使得数据中心的之间的距离较远。Peter说,早期亚马逊的数据中心之间有70毫秒的延迟,如何将数据中心之间的延迟降低?于是,亚马逊考虑到数据中心之间数据传输,以及自然条件的因素,找到了平衡的区域AZ概念,即在同一区域部署多个数据中心。
于是亚马逊在2003年开始着手考虑云业务AWS的时候,首次提出了区域(Region)和可用区(AZ)的概念。区域英文名称Region,是指云提供商的基础设施所覆盖的范围,比如你的云数据中心位于北美或者亚太,抑或欧洲。在《Gartner的云基础设施和平台服务魔力象限》报告中,如果要参与评估,会要求云提供商在说明格式中表述关于位置的要求:“按国家、公司开展业务所用的语言和可提供技术支持的语言所划分的数据中心位置,供应商必须在至少三个大洲拥有经过ISO27001审核(或同等标准)的数据中心。”所以在一个区域,云提供商会建设一组数据中心。
可用区英文简称AZ是指一个数据中心,即在一个区域(Region)中可包含多个可用区(AZ),AWS为每个区域标配至少三个可用区,比如AWS位于中国的北京区域(光环新网运营)和宁夏区域(西云数据运营),至少就有6个数据中心。
“AZ之间的距离在若干英里或几十英里之间,这样的距离是保持数据中心延迟在一毫秒的关键”,Peter说。
也就是说在保证一毫秒关键的前提下,让数据中心之间的距离拉远,来减小数据中心的相互干扰,甚至是雷电等不可预测因素同时给相近的数据中心带来相互影响。
在AZ的设计上,AWS为数据中心配置独立的网络,供配电系统,配线系统等。
所以,AZ之间尽量的互不干扰,独立系统,以及低延迟等严苛因素的配置,不仅带来的更好的冗余,也将破坏半径的影响再次降低。
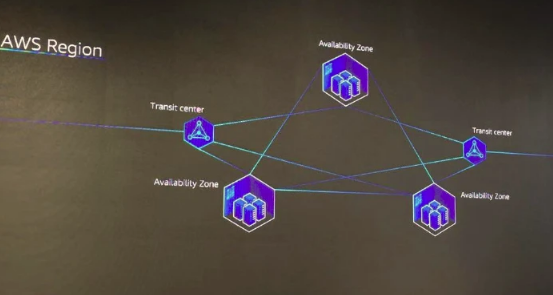
如图中所示,一个AWS区域,配备了3个独立的可用区,以及两个网络接入点(Transit Center)。
“目前,AWS在24个地理区域拥有77个可用区,并已公布计划在澳大利亚、印度、印度尼西亚、日本、西班牙和瑞士新建6个AWS区域、18个可用区”,Peter说。
同时,除了可用区架构之外,AWS也会充分考虑人对数据中心的影响。AWS数据中心执行严格的保密制度,“AZ所在的位置是严格保密的,比如所有运往AZ的硬件设备,都会首先运达一个中转中心,再由那里运往AZ所在的位置”,AWS大中华区产品部计算与存储总监周舸如是说。
云端“适用”的芯片设计
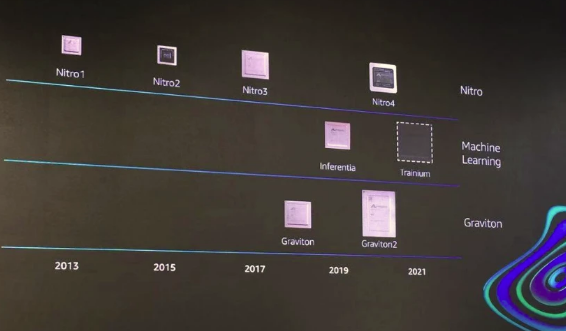
自从2015年亚马逊收购Annapurna labs后,AWS云上的芯片研发就在加速奔跑。如今,其自研的Graviton2处理器已经上市,同时Nitro系统也演进了到了第四代。
“AWS是目前在云端唯一能够提供支持英特尔、AMD、英伟达和ARM处理器的云提供商,Nitro系统起了非常关键的作用”,Peter说。
正是如此广泛的芯片支持,使得Amazon EC2计算实例,从2019年的270种跨越到了现在超过400种,并不断给用户带来更具性价比的计算实例选择。
在今年的re:Invent大会上,AWS发布了Amazon EC2 Mac实例,来支持2800万Apple开发者在云端构建macOS环境,并可以动态扩容,按需付费;基于AWS Graviton 2处理器的C6gn实例,可提供100 Gbps的网络性能,与当前基于x86的同类实例相比,性价比提高了40%。
而且,在Nitro系统的加持下,AWS专门为机器学习推出了满足模型训练和推理的高性价比芯片,比如使用AWS自研AWS Inferentia芯片的Inf1实例,为机器学习推理带来最优的性价比;以及刚刚发布的全新机器学习训练芯片AWS Trainium,与标准的AWS GPU实例相比,可带来30%的吞吐量提升,以及降低45%的单次引用成本。
为什么AWS自研了基于Arm架构的芯片后,Graviton2很快在云端获得了诸多用户的青睐?
“Graviton 2处理器跨越到了更多的领域,激活了整个生态系统,很多基于Linux系统的应用都可以快速、简单的转到Graviton上”,Peter说。
AWS在芯片设计上有自己的理解,“AWS要做的是真正满足云端性能而且省电的处理器,这是关键”,Peter解释说,“所以我们自研处理尽量做到多核,以及满足微服务的发展。”
近年来,AWS在芯片上的每一次迭代,都会给用户带来更优的计算实例性价比,性能提升的同时,整体成本也大幅降低。
在给用户带来高性价比芯片的同时,通过自研芯片的发展,AWS大大降低了其云数据中心的碳排放,降幅达88%。
结语
Peter还提及了数据中心采购供应链的多元化,以及数据中心的可再生能源对AWS云基础设施的影响。在2015年,AWS云数据中心中4个关键组件的供应商来自4个国家和地区的29个供应商,而在2020年已经变成7个国家和地区的86个供应商,多元化夯实了AWS抵御风险的能力;同时AWS也积极拥抱再生能源,如今的规模已经达到每年6.5GW,并承诺在2025年实现100%使用再生能源。























