








思考:大规模数据如何检索?
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
1)用什么数据库好?(mysql、sybase、oracle、达梦、神通、mongodb、hbase…)
2)如何解决单点故障;(lvs、F5、A10、Zookeep、MQ)
3)如何保证数据安全性;(热备、冷备、异地多活)
4)如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5)如何解决统计分析问题;(离线、近实时)
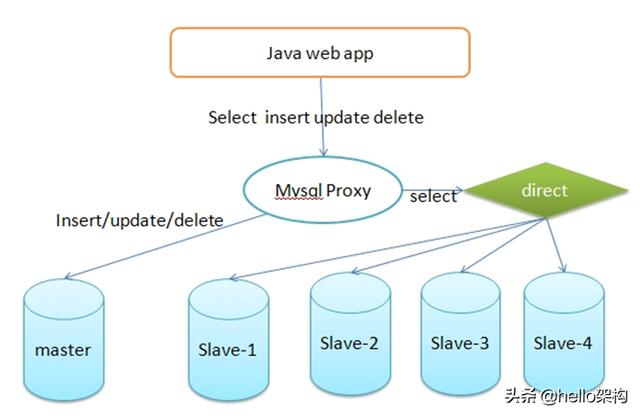
传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈:
解决要点:
1)通过主从备份解决数据安全性问题;
2)通过数据库代理中间件心跳监测,解决单点故障问题;
3)通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果
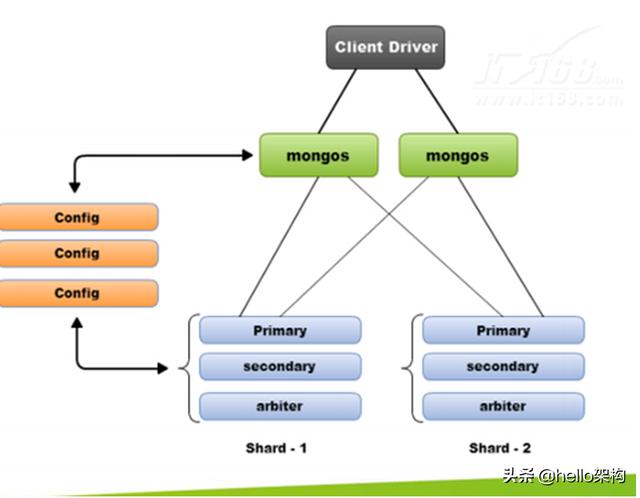
非关系型数据库的解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
解决要点:
1)通过副本备份保证数据安全性;
2)通过节点竞选机制解决单点问题;
3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
另辟蹊径——完全把数据放入内存怎么样?
我们知道,完全把数据放在内存中是不可靠的,实际上也不太现实,当我们的数据达到PB级别时,按照每个节点96G内存计算,在内存完全装满的数据情况下,我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922个
实际上,考虑到数据备份,节点数往往在2.5万台左右。成本巨大决定了其不现实!
从前面讨论我们了解到,把数据放在内存也好,不放在内存也好,都不能完完全全解决问题。
全部放在内存速度问题是解决了,但成本问题上来了。
为解决以上问题,从源头着手分析,通常会从以下方式来寻找方法:
1、存储数据时按有序存储;
2、将数据和索引分离;
3、压缩数据;
这就引出了Elasticsearch。
1. ES 基础一网打尽
1.1 ES定义
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.2 Lucene与ES关系?
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)速度要快。
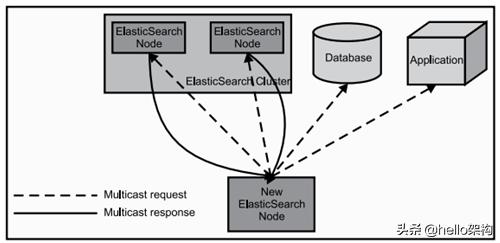
1.4 ES工作原理
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
1.5 ES核心概念
1)Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为节点。
3)Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5)全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
1.6 ES数据架构的主要概念(与关系数据库Mysql对比)
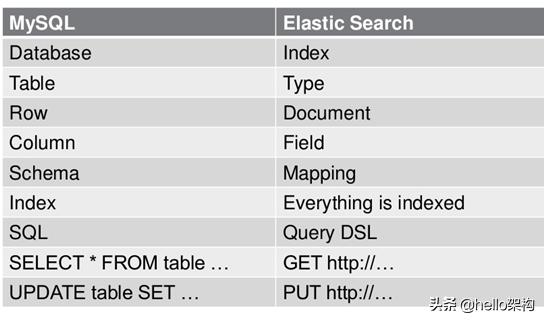
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
1.7 ELK是什么?
ELK=elasticsearch+Logstash+kibana elasticsearch:后台分布式存储以及全文检索 logstash: 日志加工、“搬运工” kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
2. ES特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
3、ES性能
3.1 性能结果展示
(1)硬件配置:
CPU 16核 AuthenticAMD内存 总量:32GB硬盘 总量:500GB 非SSD
(2)在上述硬件指标的基础上测试性能如下:
1)平均索引吞吐量: 12307docs/s(每个文档大小:40B/docs)
2)平均CPU使用率: 887.7%(16核,平均每核:55.48%)
3)构建索引大小: 3.30111 GB
4)总写入量: 20.2123 GB
5)测试总耗时: 28m 54s.
4、为什么要用ES?
4.1 ES国内外使用优秀案例
1) 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”。
2)维基百科:启动以elasticsearch为基础的核心搜索架构。
3)SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”。
4)百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群大100台机器,200个ES节点,每天导入30TB+数据。
4.2 我们也需要
实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当搜索做到一定程度时,维护和扩展起来难度就会慢慢变大,所以很多公司都会把搜索单独独立出一个模块,用ElasticSearch等来实现。
近年ElasticSearch发展迅猛,已经超越了其最初的纯搜索引擎的角色,现在已经增加了数据聚合分析(aggregation)和可视化的特性,如果你有数百万的文档需要通过关键词进行定位时,ElasticSearch肯定是最佳选择。当然,如果你的文档是JSON的,你也可以把ElasticSearch当作一种“NoSQL数据库”, 应用ElasticSearch数据聚合分析(aggregation)的特性,针对数据进行多维度的分析。
ES在某些场景下替代传统DB
个人以为Elasticsearch作为内部存储来说还是不错的,效率也基本能够满足,在某些方面替代传统DB也是可以的,前提是你的业务不对操作的事性务有特殊要求;而权限管理也不用那么细,因为ES的权限这块还不完善。
由于我们对ES的应用场景仅仅是在于对某段时间内的数据聚合操作,没有大量的单文档请求(比如通过userid来找到一个用户的文档,类似于NoSQL的应用场景),所以能否替代NoSQL还需要各位自己的测试。如果让我选择的话,我会尝试使用ES来替代传统的NoSQL,因为它的横向扩展机制太方便了。
5. ES的应用场景是怎样的?
通常我们面临问题有两个:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文检索服务,需要使用ES。
一线公司ES使用场景:
1)新浪ES 如何分析处理32亿条实时日志https://dockone.io/article/505
2)阿里ES 构建挖财自己的日志采集和分析体系https://afoo.me/columns/tec/logging-platform-spec.html
3)有赞ES 业务日志处理https://tech.youzan.com/you-zan-tong-ri-zhi-ping-tai-chu-tan/
4)ES实现站内搜索https://www.wtoutiao.com/p/13bkqiZ.html
【凡本网注明来源非中国IDC圈的作品,均转载自其它媒体,目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。】























