现如今的企业组织机构正在大规模的采用AI人工智能应用程序来解析不断呈指数级增长的庞大数据量,这不仅要求极高,并且需要具备强大的并行处理功能,因此原来的标准化CPU已然无法充分执行许多AI解析任务了。有鉴于此,当企业数据中心在接近或达到服务器性能的瓶颈局限时,究竟应该相应的采取哪些有效的应对措施呢?
在本文中,我们将帮助您企业数据中心准备并应对由AI应用程序为企业本地部署环境和云基础架构所带来的限制。同时,我们还采访了数据中心业界的同行们,邀请他们提供了相关的指导性建议,其中包括着重强调了企业数据中心与服务器供应商密切合作的重要性,这些服务器供应商可以为您的企业从早期阶段尽快过渡到稳步的高级生产阶段,进而充分利用AI功能提供相应的指导。
当前的企业组织机构正在积极努力的应对众多的变数,以确定他们对使用由深度学习时带来的能够提供新的洞察见解的人工智能(AI)应用程序到底应该采取怎样的立场。而这一领域在当下可以说是充满了无限的商机,不采取积极的行动可能会演变成商业灾难,因为企业的竞争对手们正在收集并分析处理海量以前无法获得的数据信息,来扩大其客户群。大多数企业组织都已然意识到了这一严峻的挑战,故而他们的业务部门、IT员工、数据科学家和开发人员们都在共同努力,以确定企业的人工智能战略。
在某种程度上,采用AI战略的企业将逐步体验到在利用AI应用程序方面更为先进的领军企业们过往的经历:他们的服务器性能将遭遇到瓶颈局限问题。人工智能应用程序,特别是深度学习系统可以对当下呈指数级不断增长的海量数据信息进行分析,但这些系统要求非常高,并且需要具备强大的并行处理能力,故而越来越多的标准化CPU已然无法充分执行这些AI任务了。早期阶段和高级阶段的AI用户在某些时候将不得不彻底改造其服务器基础设施以实现所需的相关性能。
因此,IDC建议正在开发AI功能或扩展现有AI功能的企业组织机构应以严格控制的方式解决这一服务器性能瓶颈问题。务必要在充分掌握相关细节的前提下实施下一步的基础设施迁移。此外,我们建议他们务必要与其服务器供应商密切合作,这些服务器供应商可以为企业客户从早期阶段尽快过渡到稳步的高级生产阶段,进而充分利用AI功能提供相应的指导。
IDC发现,大多数处于概念验证(POC)测试或生产模式的人工智能和深度学习应用程序的企业在某种程度上已经达到了 “服务器基础设施瓶颈限制”的水平——有时在这些企业迁移到不同的服务器基础设施后,会不止一次的出现基础设施瓶颈局限性的问题。
IDC采访了相关的企业组织当他们在其现有的企业内部部署服务器基础架构上开始运行AI应用程序时所经历的情况。77.1%的受访者表示他们在内部服务器部署基础设施上运行AI遇到了一个或多个限制。在采用了认知软件的云用户中,90.3%的企业遇到了这种限制。下表1列出了在企业内部部署服务器环境和云基础架构中运行AI应用程序的相关限制。
表1:基础架构运行AI应用程序的瓶颈限制(排名分主次顺序)
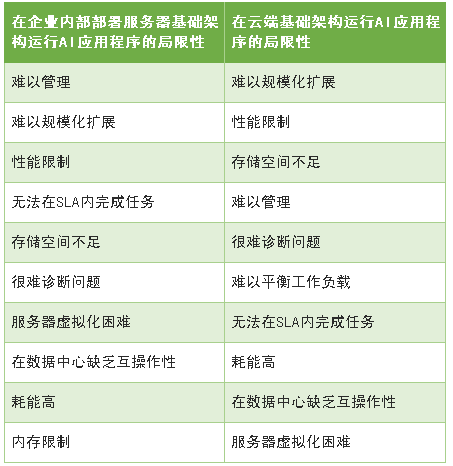
资料来源:《认知服务器基础架构调查》2017年6月,IDC
正是由于这些基础设施的瓶颈局限问题的出现,很多企业很快经历了代际转变。尽管人工智能应用程序和深度学习的兴起仅仅只有几年时间,但IDC发现,已有22.8%的企业在采用第三代服务器基础设施来运行其人工智能应用程序了,而37.6%的企业在使用第二代服务器基础设施,39.6%的企业则在使用第一代的服务器基础设施。上述这些调查百分比表明了当下的企业客户正在寻找合适的基础设施。而下表2则列出了AI服务器基础架构最常出现的代际。
表2:人工智能服务器基础设施最常见的代际(排名分顺序)
资料来源:《认知服务器基础架构调查》2017年6月,IDC
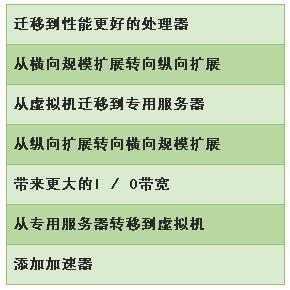
转向具有更高处理器性能(通常所采取的最常见的措施)、更大的I / O带宽和加速器的系统是一个合理的决定。但是这些数据也表明了理想配置所存在的不确定性。一些企业已经尝试了横向规模化扩展,并纵向扩展;而另外一些企业则采取了相反的方案。其他某些迁移从虚拟机开始,然后转移到专用服务器,而其他一些同行却与此相反。
这些矛盾的举措其实并不像其看起来那么奇怪。当前的企业组织不仅在AI软件上进行试验,而且同时也在基础设施上进行试运行。一些企业已经开始采用横向的规模化扩展配置,并且随着解决方案的日趋成熟,他们决定需要更高的性能,而这些性能能够在数据中心的现有扩展系统中获得。其他一些企业则在扩展系统的一个分区上启动了POC,并在解决方案进入下一阶段时决定将其转移到一个单插槽或双插槽的服务器集群。同样的,一款解决方案可能已经在虚拟机中开发出来,然后被迁移到专用的服务器上,以便在有些绝缘隔热的的环境中进一步开发(很多企业更倾向于在早期阶段如此进行)。
IDC认为,对于早期的实验和开发而言,所有这些迁移的举措都是有道理的。利用现有的环境意味着延迟投资于新的服务器基础设施,直到企业明确了什么是最为恰当的配置为止。但是,一旦应用程序接近运行并准备投入生产,就需要及时的做出合理的基础架构方面的决策了,以避免触及基础设施的瓶颈。
根据来自已经运行了AI应用程序的企业用户们的反馈,我们认为:认知应用程序的理想基础架构配置是一组具有加速器的单路或双路服务器,不过,企业也还可以根据实际业务需要在稍后阶段添加加速器。中型系统集群也是可行的,但只有在工作负载迅速的规模化扩展的情况下才是相关的。其他配置可能也是可行的。从对于企业用户的研究中可以清楚地看出,超融合系统和虚拟机已被证明对认知应用的影响较小。