








本次分享会给大家系统地介绍10P+金融数据迁移的整个过程。下面是对这次线上分享的文字总结,希望对想了解HBase跨机房迁移技术的网友有帮助。
一、HBase知识介绍
考虑到来听分享的大部分都是MySQL DBA,因此这里做了个简单的HBase相关介绍,主要介绍了如下三个方面的内容:
1、HBase简介
HBase是基于google bigtable的开源实现,又称为hadoop database,具有高性能、高可用、易伸缩等特点,是一个面向列的分布式存储系统,可以在廉价PC Server的机器上搭建海量存储服务。
随着数据量的不断增大,查询和写入的性能并不会出现明显的下降,可以说是目前各大企业构建数据中心很好的选择。

2、HBase的优缺点
HBase的优点
总结了HBase的几个优点如下:
列可以动态增加
其实更准确的说,HBase是面向列族的数据库,一个表可以有多个列族,而每个列族下面可以有非常多的列,也就是说列族下面的列可以动态增加或者减少。
卓越的写入性能
HBase采用的是LSM类型系统结构,写入都是先写内存,后面再异步批量刷新到磁盘,因此写入性能非常好。并且这种写入性能很容易通过扩容机器提升。
海量存储
HBase就是为海量存储而生的,由于其优秀的架构设计,使得数据量的不断增长,在查询时延方面并不会下降特别多。因此HBase在海量数据的场景下,优势非常明显。
极易扩展
HBase由于其架构的特性(后端采用HDFS存储,借助ZK的相关特性),HBase极易扩展,通过添加节点,来增加存储量和提升写入性能,使得HBase极具伸缩性。
HBase的缺点
总结了HBase的缺点如下:
HBase原生不支持SQL
HBase原生并不支持SQL,业务接入HBase需要通过接口做一些改造,这在一定程度上还是不太友好。虽然目前有一些组件也为HBase提供一些接口支持,比如phoenix。但是就我们的测试来看,稳定性仍然是一个很大的问题。
查询延迟比DB大
HBase比较多的应用是通过廉价的PC Sever构建海量存储服务,而目前DB的标配基本都是SSD盘,DB的延迟可以做到0.x个毫秒,而基于廉价PC Server构建的海量存储服务的延迟一般在几十毫秒到上百毫秒之间。
当然HBase也可以采用SSD盘来构建海量存储,但这种成本就比较高。目前HBase已经支持了异构存储功能,可以将热数据存储到SSD,冷数据存储到SATA,这是一个很好的方案。
RegionServer单点
运维过RegionServer的同学都可能深有体会,表的某一个region只能分配到某一台RegionSever的机器上,因此,当某一台RegionServer异常的时候,上面的Region肯定会有影响,尤其是当一个RegionServer上有超过1000个region的时候,影响可能会达到几分钟。这个单点的问题还是一个比较大的硬伤。
目前HBase2.0版本已经引入了Region Replica的支持,但是由于需要更多的资源和强读一致性的问题,业界真正在生产环境使用这个功能的非常少。比较多的是采用集群容灾方式,在业务层做切换,目前我们就是采用这种方式,以减少单个RegionServer异常对业务造成影响。
3、HBase架构
HBase的架构图如下:

上面是比较经典的HBase架构图,偷个懒,直接借来用一下,从图中我们可以看出HBase的架构层次还是很清晰的。可以把这个架构分成三层来看(暂时把Zookeeper和Master忽略):
第一层:客户端层
客户端层主要是业务发起的地方,可以是写入发起端,也可以是业务查询端,这个比较好理解,就是HBase的调用方。
第二层:RegionServer层
RegionServer提供所有访问层的功能,你可以简单地理解为那一层是路由层、缓存层、引擎层等。所有对HBase的读写请求都需要经过RegionServer层。
第三层:存储层
HBase底层采用HDFS作为存储层,所有的数据都存储在HDFS,前面说的HBase极具伸缩性,很大程度上得益于底层采用的HDFS存储。
4、一个DBA都能理解的HBase使用场景
上面讲了那么多,那么HBase到底是怎么使用的?
其实HBase可以用在很多的场景中,比较消息订单、时序DB、对象存储、推荐画像等。这里讲一个DB最能理解的使用场景,那就是存储需要长久保存的海量历史数据。
比如:对于金融数据,由于监管的要求,至少需要保留5年,对于支付的订单、支持流水等数据,本身数据量非常大,并且历史数据还有查询需求。
这种数据如果保留在关系型的DB中,历史DB的扩容、迁移、维护,还有访问将会是DBA的噩梦。但是如果这种数据保留在HBase中,就会非常的方便。
二、HBase跨机房迁移
1、背景及挑战
背景
这次HBase跨机房迁移的背景是机房裁撤,必须在规定的时间内把HBase集群从裁撤机房迁移到新机房。
挑战
针对这次HBase跨机房迁移,我们主要面临如下几个挑战:
经验缺乏
在做这次迁移之前,我们团队缺乏HBase大规模数据迁移经验,而我自己之前主要做MySQL数据库相关的工作,对HBase也只是做过一些研究,实战经验并不多。只能摸着石头过河。
业务不能中断
由于是金融业务,业务上是不能出现中断的,因此,必须确保此次迁移平滑进行。
数据一致性
金融数据必须保证数据的准确性和一致性,数据不能少,也不能错。数据一致性我们始终是放在最重要的位置上。
数据量大
此次迁移涉及到10P+的数据,并且不能影响现有的业务,这本身就是一个蛮大的挑战。
2、方案选型
此次迁移,由于缺乏经验,我们研究了很多业界的一些迁移的方案和案例,总结出如下几个方案,我们最终选择了SnapShot+集群写的方案:
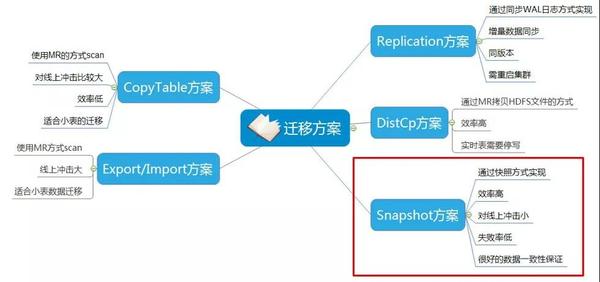
下面我们分别来看看各个方案的具体情况:
Replication方案
Replication和MySQL同步的方案比较类似,也是通过同步日志(WAL日志)的方式实现HBase数据的增量同步,这个方案主要是基于增量数据的同步,并且主从集群版本相同,启用replication功能还需要重启集群。
我们这次迁移涉及到比较大的版本变动(之前的集群版本比较老),并且有10P+的历史数据,并且这种方式和我目前的集群双写方案也不兼容,因此我们没有采用这个方案。
Distcp方案
Distcp是通过MR拷贝HDFS底层文件的形式实现数据的迁移,由于不涉及到RegionServer层,因此效率非常高,非常适合历史数据(不会再有修改的数据)的迁移。针对实时表的话,则需要停写才能确保数据的一致性。
CopyTable方案和Export/Import方案
CopyTable和Export方案类似,都是通过MR去scan表的方式实现,不同的是,CopyTable通过MR scan出数据后直接写入另外一个集群,实现数据的迁移。而Export则是scan后保存为文件,传输到另外一个集群后再做import的操作,从而实现数据的迁移。
这种由于需要通过RegionServer层来做数据的scan,如果表很大的话,会对线上的读写有比较大的影响。这种方案比较适合小表的迁移。
SnapShot方案
SnapShot是通过快照来实现HBase数据一致性迁移,这种方式在创建快照的时候会创建文件的引用指针,在传输的时候,通过MR直接拷贝底层HDFS文件,因此创建非常快,效率很高,并且对线上冲击很小,能很好的保证数据的一致性。
SnapShot是目前各个commiter比较推荐的迁移数据方式,再加上这种方案和我们的集群双写方案完全兼容,因此我们最终采用了这个方案。
备注:SnapShot的方案特别需要注意的是,hbase.hstore.time.to.purge.deletes设置的时间一定要比表整体的迁移时间要长(包含做快照、传输快照和导入快照总时间),否则会导致数据冗余的问题。
3、迁移的架构图和详细流程
迁移的架构图
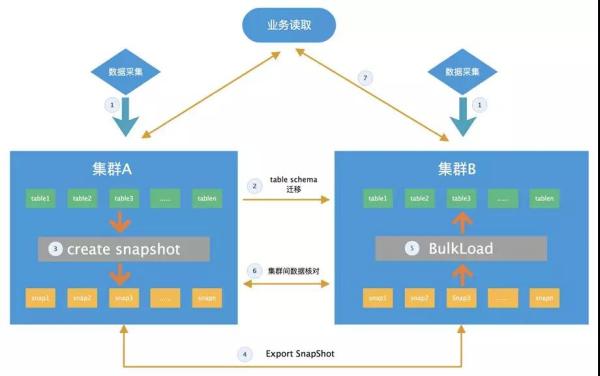
迁移的详细流程
如上图所示,我们迁移的详细流程如下:
将表结构同步从A机房同步到B机房; 启用集群双写; 针对某一类表创建SnapShot; 创建好SnapShot后,使用exportsnapshot工具将快照迁移到新集群; 使用bulkload的方式将快照涉及的HFile文件导入到新集群; 使用集群间数据比对工具,对表做集群间数据校验; 数据校验通过以后,就可以开始灰度切换业务。
4、注意事项和应对策略
进行大规模的数据迁移,还是有比较多的注意事项,下面是需要注意的事项和我们的应对措施:
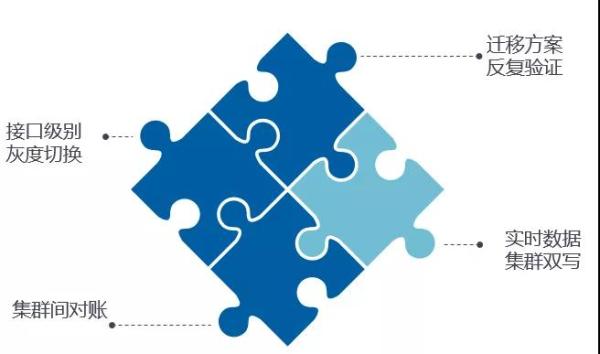
数据一致性性问题
在迁移中,数据一致性问题是首先要考虑的问题,加上我们迁移的是金融数据,一致性问题更是我们考虑的重点。为了保证数据的一致性,我们的应对措施如下:
在制定迁移方案之前就将数据一致性列在最重要的位置,充分考虑数据一致性问题; 在方案制定后,进行各个场景的测试,确保数据的一致性; 集群双写保证增量数据一致,通过snapshot来保证历史数据的一致性; 使用集群间数据对账来兜底,保证数据最终一致性。
业务连续性问题
针对业务的连续性问题,我们是对接口做了细粒度的改造,目前使得切换粒度支持表级别的切换。我们在切换的时候也根据业务的重要优先级以及访问量,来做接口级别的跨机房灰度切换,确保对业务的影响最小。
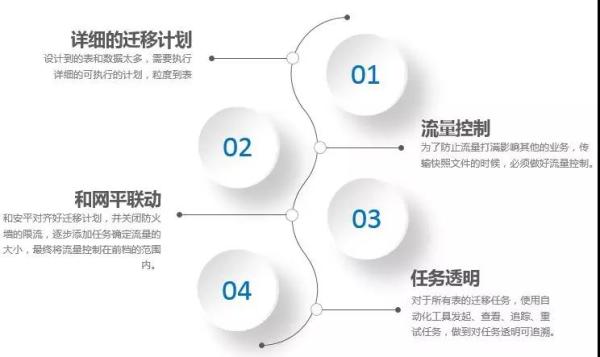
流量控制问题
对于如此大规模的数据迁移,我们比较担心的是跨机房传输快照的时候,把机房带宽打满,导致其他的业务受影响。因此我们的应对策略有两个:
传输快照的时候,添加-bandwidth参数做好流控; 和网平联动,同步迁移计划,关闭防火墙限流,并密切关注机房间的流量,逐步灰度任务,确保流量控制在60%以下。
数据量大涉及表多的问题
针对表数据量大和表多的问题,主要担心的是迁移的时候会造成遗漏,或者迁移任务失败了后遗漏了。因此这里主要是做好任务管理,我们主要做了两个事情来保证项目的进展和任务:
制定详细的迁移计划,粒度细化到表; 开发自动化迁移工具,实现自动化任务发起、查看、追踪、和重试。
5、跨机房经验总结
在做HBase跨机房迁移的过程中,我们遇到了非常多的问题,也积累了非常多的经验,我们对于迁移的流程、注意事项、使用到的技术、部署等都做了总结,这里列出来方便大家学习,有兴趣的网友可以根据主题做对应的阅读:
HBase金融大数据乾坤大挪移 www.jianshu.com/p/cb4a645dd66a HDFS异构存储实战 www.jianshu.com/p/167d7677a050 HBase隔离方案实战 www.jianshu.com/p/04d56a2c8b5c 玩转HBase快照 www.jianshu.com/p/8d091591d872 HBase生产环境部署指南 www.jianshu.com/p/9533ac9de0fe dfs.datanode.du.reserved引发的问题 www.jianshu.com/p/508449d8f12c SSD耗尽问题 www.jianshu.com/p/167d7677a050 MapReduce相关问题排查思路 www.jianshu.com/p/ebd469da07d2
三、HBase SnapShot深入介绍
1、SanpShot原理简介
HBase的SnapShot可以理解为是原数据的指针,包含表对应的元数据和涉及到的HFile相关的信息。
之所以创建快照后,HBase能根据这些数据的指针还原出做快照时刻的数据,是因为HBase数据文件一旦落盘,就不允许在原地做修改。如果要修改,则必须追加写入新的文件。
还有一点需要注意的地方,就是HBase本身也会对HFile文件做修改,因为涉及到文件的合并。这里HBase会在HFile文件合并之前将对应的表复制到archive目录下,确保HFile文件的完整性。
2、SnapShot详细流程
由于HBase表相关的数据以region的形式分布在多台RegionServer上,在做快照的时候,必须保证快照的要么都成功,或者都失败,不能出现部分RegionSever创建快照成功,部分RegionServer创建快照失败的情况。
HBase采用两阶段提交的方式来创建快照,分别是prepare阶段和commit阶段,当创建快照异常的时候,还有个abord阶段:
Step 1:客户端向master发起表创建快照的请求;
Step 2:prepare阶段,master会在zookeeper上创建/acquired-snapshotname(简写为/acquired_sname)节点,并记录表相关的信息;
Step 3:RegionServer检测到/acquired_sname节点,并根据上面表的信息确认该RegionServer是否含有那个表的Region,如果有则参与到快照的创建中来,如果没有则忽略;
Step 4:RegionServer参与parepare阶段的时候,首先会加一把全局锁,此时不允许这个表有数据写入、更新和删除,将memstore中的数据flush到文件中,并为涉及到的所有HFile文件创建引用指针,这些指针元数据便是snapshot,并将这些元数据以及表相关信息写入到临时目录中;
Step 5:在第4步完成后,便会在/acquired_sname新建RegionServer对应的子节点,表示该RegionServer完成了prepare阶段;
Step 6:当master发现所有的涉及到的RegionServer都完成了prepare阶段的工作后,就会发起commit阶段的操作;
Step 7:在commit阶段,master会在zookeeper上创建/reached-snapshotname(简写为/reached-sname),该表涉及的RegionSever监听到事件后,就会启动commit阶段的工作,将临时目录中的snapshot的数据写入到正式的目录,操作完成后便会在/reached-sname新建该RegionServer对应的子节点;
Step 8:当master发现所有涉及到的RegionServer都完成了commit阶段的工作后,master还需要做一次汇总操作,汇总操作完成后,整个snapshot的创建就完成了。
Step 9:如果在一定时间内前面阶段有的regionserver没有完成对应的操作,则会进入abord阶段,在abord阶段,master会在zookeeper上创建/abord_snapshotname(简称/abord_sname),涉及的RegionServer会进行创建快照流程的回滚操作,即将临时文件夹的快照内容删除。
3、SanpShot实战
snapshot的使用相对还是比较简单,下面来实战一下:
创建snapshot
snapshot 'tableName', 'snapshotName'
备注:在hbase shell中执行。
查看snapshot
list_snapshots 查找以map开头的snapshot list_snapshots 'map.*'
删除snapshot
delete_snapshot 'snapshotName'
迁移snapshot
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \ -snapshot snapshot_src_table \ -copy-from hdfs://src-hbase-root-dir/hbase\ -copy-to hdfs://dst-hbase-root-dir/hbase\ -mappers 20 \ -bandwidth 1024
这种方式用于将快照表迁移到另外一个集群的时候使用,使用MR进行数据的拷贝,速度很快,使用的时候记得要设置好bandwidth参数,以免由于网络打满导致的线上业务故障。
如果没有混布MR,则还需要搭建一个MR集群,并且命令行中需要再加入MR集群的相关参数。
恢复snapshot
restore_snapshot ‘snapshotName’
备注:这种方式需要对表进行过disable才能进行restore_snapshot的操作,如果这个还在写入数据,则需要采用bulkload的方式导入。
将snapshot使用bulkload的方式导入
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \ -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024 \ hdfs://dst-hbase-root-dir/hbase/archive/datapath/tablename/filename tablename
备注:这种方式需要将所有的文件进行遍历并全部通过bulkload导入,上面的只是一个文件的导入,这种方式不需要disable表。
Q & A
Q:前面讲的除了业务灰度切换的过程,从开始迁移到数据检验的自动化部分有更多分享吗?
A:除了业务灰度切换的过程,从开始迁移到数据检验其实是代码实现的一个过程,比如说我们第一步先创建快照,这样就很容易做代码实现,成功后会启用exportsnapshot的方式把快照从一个集群迁到另一个集群,把snapshot的名字传进去,直接通过传参数的方式在程序里实现。bulkload的导入也是一样的,在确定导入成功后,把原来的快照删除就可以做数据的校验、比对了。
【凡本网注明来源非中国IDC圈的作品,均转载自其它媒体,目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。】























